
Automatic Field-of-View Expansion using Deep Features and Image Stitching
基于深度特征和图像拼接的视野自动扩展
缺点:图像必须有良好特征,且具有大量特征的数据集
使用场合:对纪念碑或建筑的视野扩展
关键技术:NetVLAD层提取全局的特征向量
主要框架:VGG-16+NetVLAD层
简介
该方法分为图像检索和图像拼接两个步骤。
-
我们为指定的地标生成字典。
-
对于字典中的每幅图像,使用训练好的NetVLAD描述符生成全局特征向量。
-
基于全局特征向量的相似性,对输入图像进行K近邻搜索。
-
K个图像被用作用于视场扩展的候选图像。
-
对于每个候选图像,使用特征匹配来评估细节相似度。如果匹配特征的数量超过阈值,使用图像拼接方法来扩大视野。
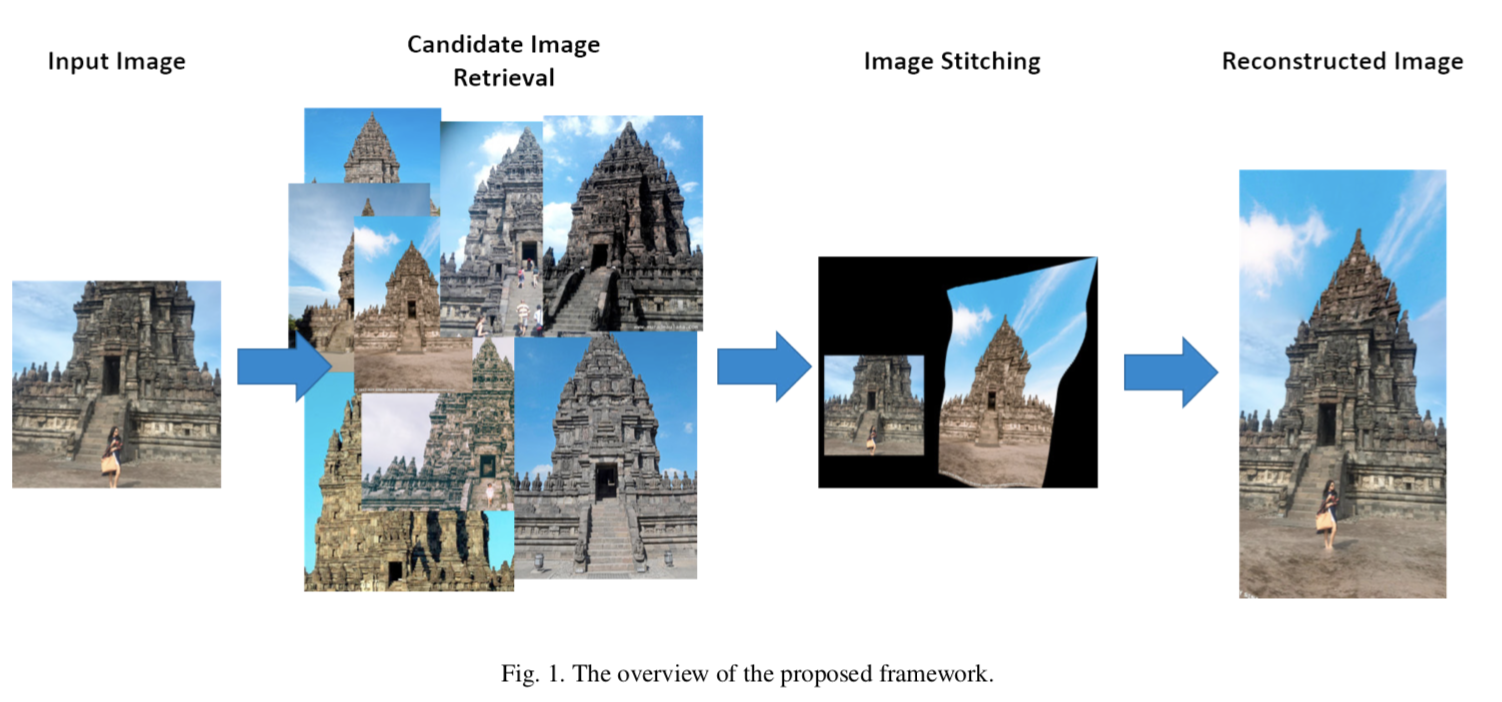
图像检索
将NetVLAD层集成到CNN架构中,删除了最后一个卷积层,并附加了NetVLAD层作为替换层,CNN架构为VGG-16,用于训练的数据集。
NetVLAD方法通过添加受VLAD3启发的池化层,将每个输入图像的提取局部描述子聚合到单个全局描述子中。
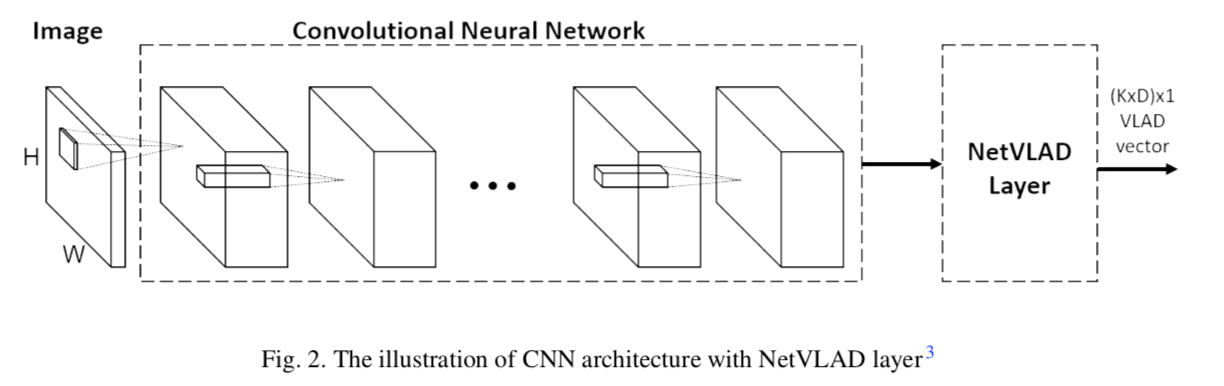
使用NetVLAD体系结构中的参数,我们可以为每幅图像生成全局特征。
因此,我们可以搜索全局特征相似度高的候选图像。对于每个候选图像,提取SIFT局部特征以衡量是否可以同时拼接两幅图像。
我们测量输入图像和候选图像之间对应的特征数量。采用二值化阈值来判断候选图像是否拼接。
图像拼接
采用APAP的图像拼接方法,使用移动直接线性变换(DLT)对不同的图像网格进行局部投影,是减少图像边界周围的重影伪影。缝合方法的思想使用位置依赖的单应性H 对每个像素x进行变换。
局限性
该方法对提取的良好特征具有较高的依赖性,可以拼接成一对图像。因此,它只能应用于具有大量特征的数据集,例如纪念碑或建筑。